
In our previous blog, The Fundamentals Of MLOps – The Enabler Of Quality Outcomes In Production Environments, we introduced you to MLOps and its significance in an intelligence-driven DevOps ecosystem. MLOps is gaining popularity since it helps standardize and streamline the ML modeling lifecycle.
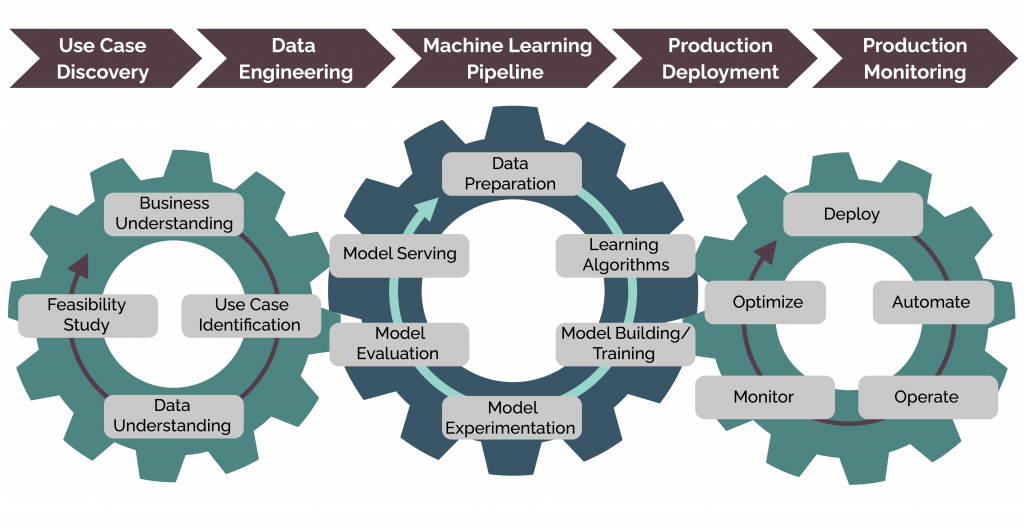 From development and deployment until maintenance, various tools and their features can be implemented to achieve the best outcomes. Organizations shouldn’t depend on just one tool but combine the most valuable features of multiple tools for:
From development and deployment until maintenance, various tools and their features can be implemented to achieve the best outcomes. Organizations shouldn’t depend on just one tool but combine the most valuable features of multiple tools for:
 This post discusses some key pointers to help you pick the right MLOps tools for your project.
This post discusses some key pointers to help you pick the right MLOps tools for your project.
Considerations for Choosing MLOps Tools
When organizations deploy real-world projects, there is a vast difference between individual data scientists working on isolated datasets on local machines and Data science teams deploying models in a production environment. These models need to be reproducible, maintainable, and auditable later on. MLOps tools help converge various functionalities and connect the dots through unified collaboration.
MLOps Tools help in these Areas
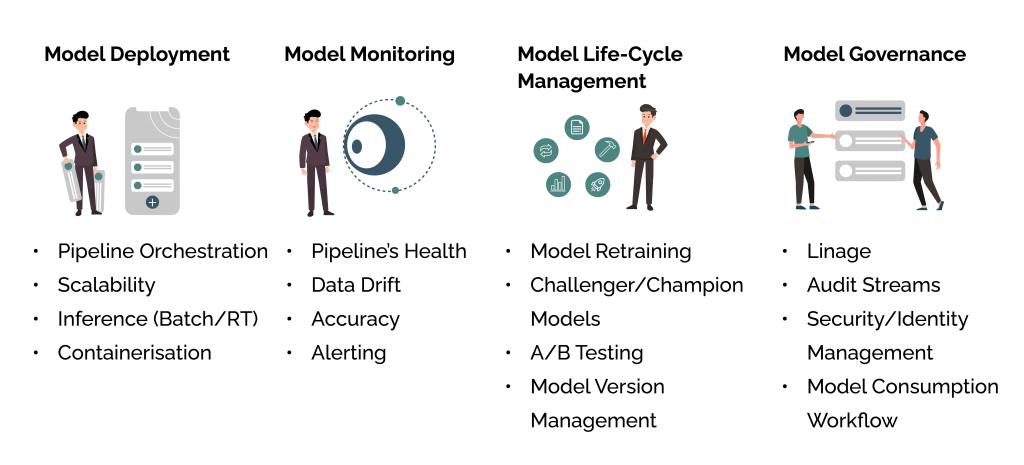 Resulting in:
Resulting in:
• 30% faster time-to-market
• 50% lower new release failure rate
• 40% shorter lead times between fixes
• Up to 40% Improvement in the average Time-to-Recovery
Radiant’s Top Recommendations:
1. Databricks MLflow
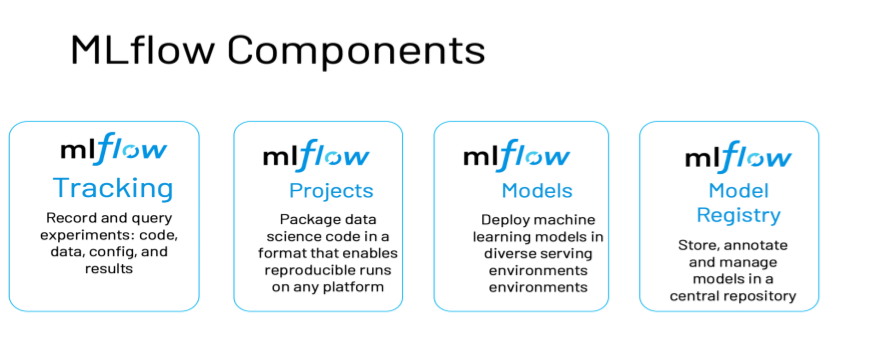
MLflow is an open-source tool that lets you manage the entire machine learning lifecycle, including experimentation, deployment, reproducibility, and a central model registry. MLflow is suitable for individual data scientists and teams of any size. This platform is library-agnostic and can be implemented with any programming language.
Components
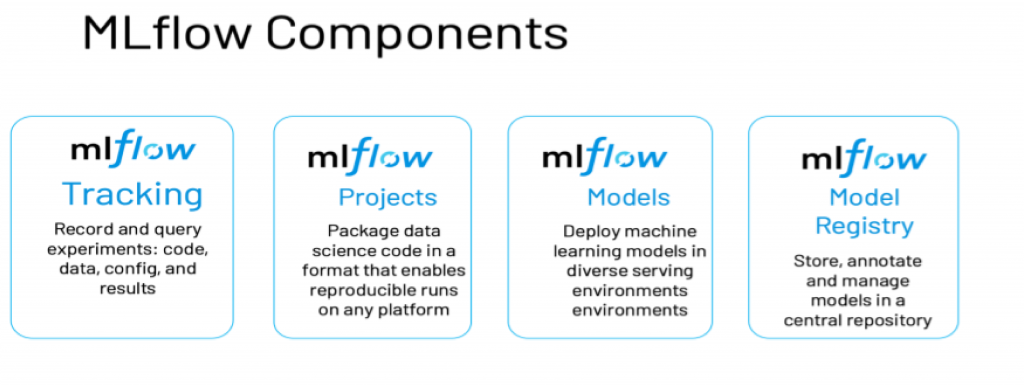 Image source: Databricks
Image source: Databricks
Features: MLflow comprises four primary features that help track and organizes experiments.
MLflow Tracking – This feature offers an API and UI for logging parameters, metrics, code versions, and artifacts when running machine learning code. It lets you visualize and compare results as well.
MLflow Projects – With this, you can package ML code in a reusable form that can be transferred to production or shared with other data scientists.
MLflow Models – This lets you manage and deploy models from different ML libraries to a gamut of model-serving and inference platforms.
MLflow Model Registry – This central model store helps manage an MLflow Model’s entire lifecycle. The processes include model versioning, stage transitions, and annotations.
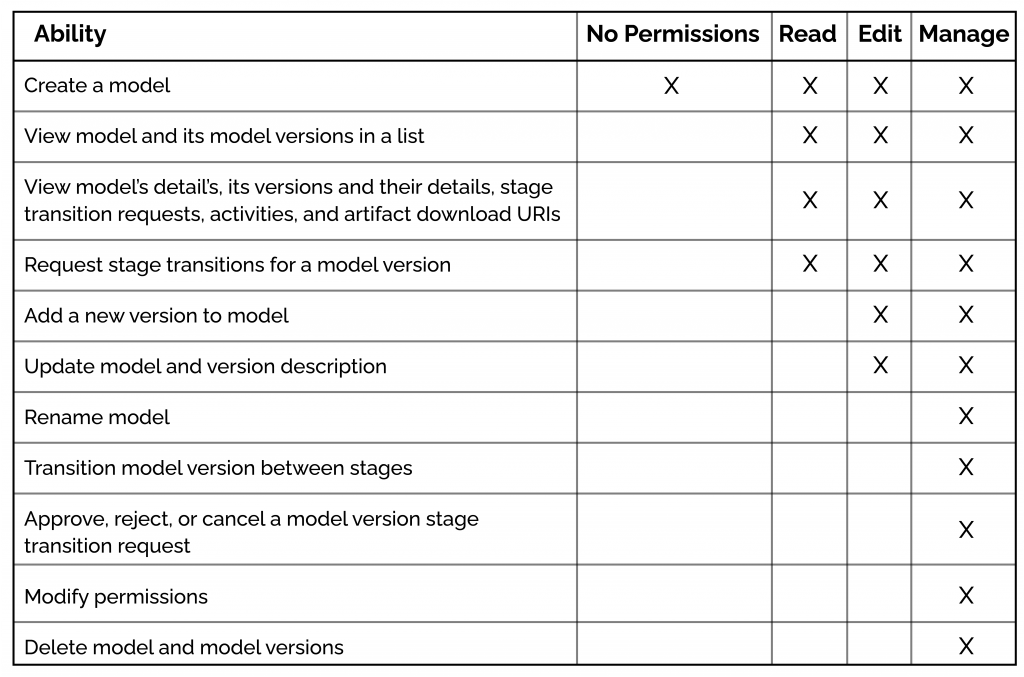
The Model Registry capabilities are given below.
Architecture
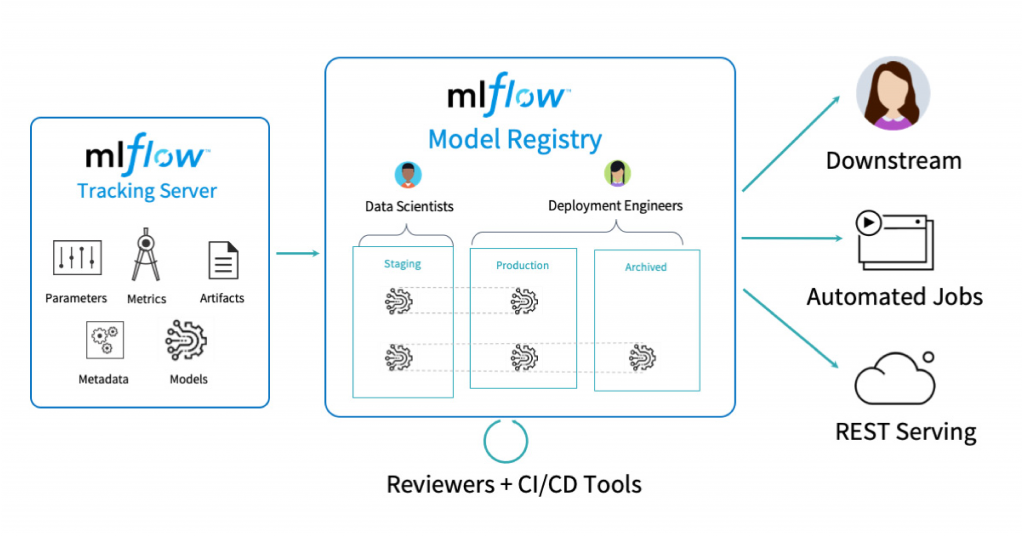 Image source: slacker news
Image source: slacker news
The MLflow tracking server offers the ability to track metrics, artifacts, and parameters for experiments. It helps package models and reproducible ML projects. You can deploy models to real-time serving or batch platforms. The MLflow Model Registry [AWS] [Azure] represents a central repository to manage staging, production, and archiving.
On-Premise and Cloud Deployment
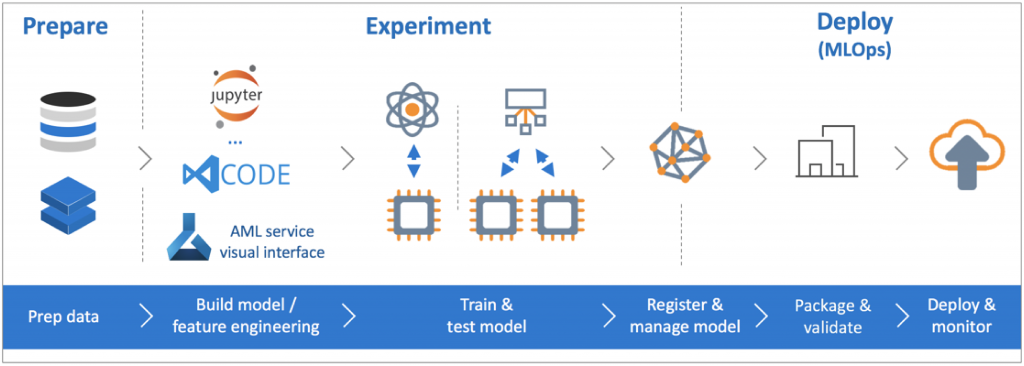 Image source: LG collection
Image source: LG collection
MLflow can be deployed on cloud platform services such as Azure and AWS. It can be deployed on container-based REST servers for on-prem, and continuous deployment can be executed using Spark streaming.
2. Kubeflow
Kubeflow is an open-source machine learning toolkit that works using Kubernetes. Kubernetes standardizes software delivery at scale, and Kubeflow provides the cloud-native interface between K8s and data science tools like libraries, frameworks, pipelines, notebooks, etc., to combine Ml and Ops.
Components
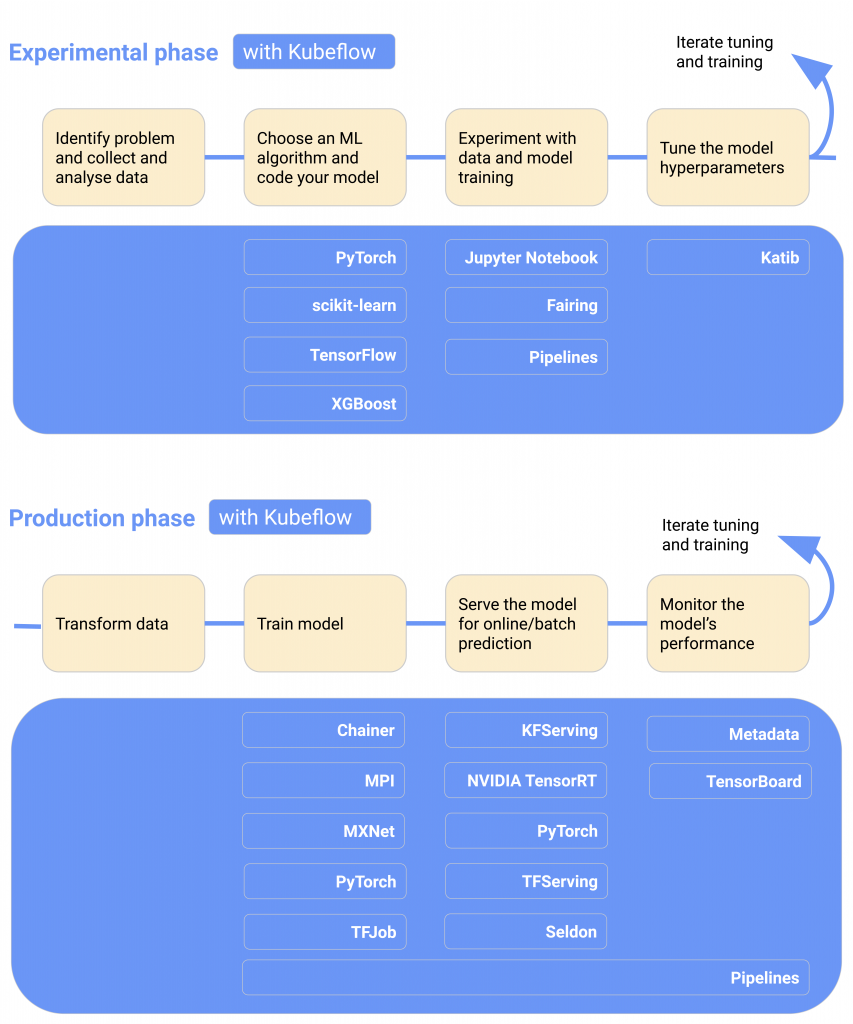 Image source: kubeflo
Image source: kubeflo
• Kubeflow dashboard: This multi-user dashboard offers role-based access control (RBAC) to the Data scientists and Ops team.
• Jupyter notebooks: Data scientists can quickly access the Jupyter notebook servers from the dashboard that have allocated GPUs and storage.
• Kubeflow pipelines: Pipelines can map dependencies between ML workflow components where each component is a containerized piece of ML code.
• TensorFlow: This includes TensorFlow training, TensorFlow serving, and even TensorBoard.
• ML libraries & Frameworks: These include PyTorch and MXNet XGBoost MPI for distributed training. Model serving is done using KFserving, Seldon Core, and more.
• Experiment Tracker: This component helps store the results of a Kubeflow pipeline run using specific parameters. These results can be easily compared and replicated later.
• Hyperparameter Tuner: Katib is used for hyperparameter tuning, which runs pipelines with different hyperparameters (e.g., learning rate) optimized for the best ML modeling.
Features
1. Kubeflow supports a user interface (UI) for managing and tracking experiments, jobs, and runs.
2. An engine schedules multi-step ML workflows.
3. An SDK defines and manipulates pipelines and components.
4. Notebooks help interact with the system using the SDK.
Architecture
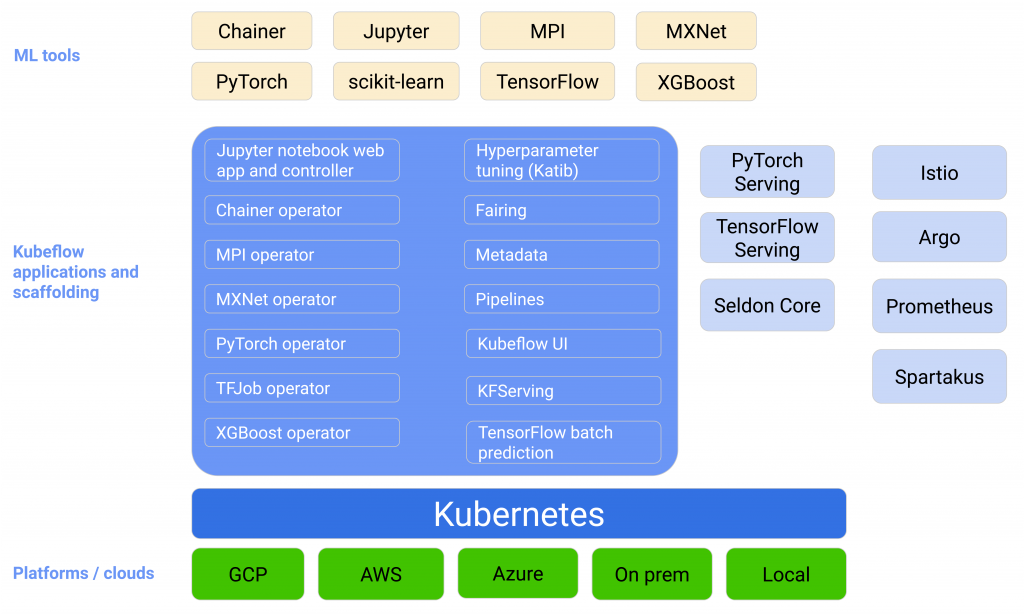 Image source: kubeflow
Image source: kubeflow
Kubeflow is built on Kubernetes, which supports AWS, Azure, and on-prem deployments. It helps scale and manage complex systems. The Kubeflow configuration interfaces let you specify the ML tools that assist in the workflow. The Kubeflow applications and scaffolding layer manage the various components and functionalities of the following ML flow.
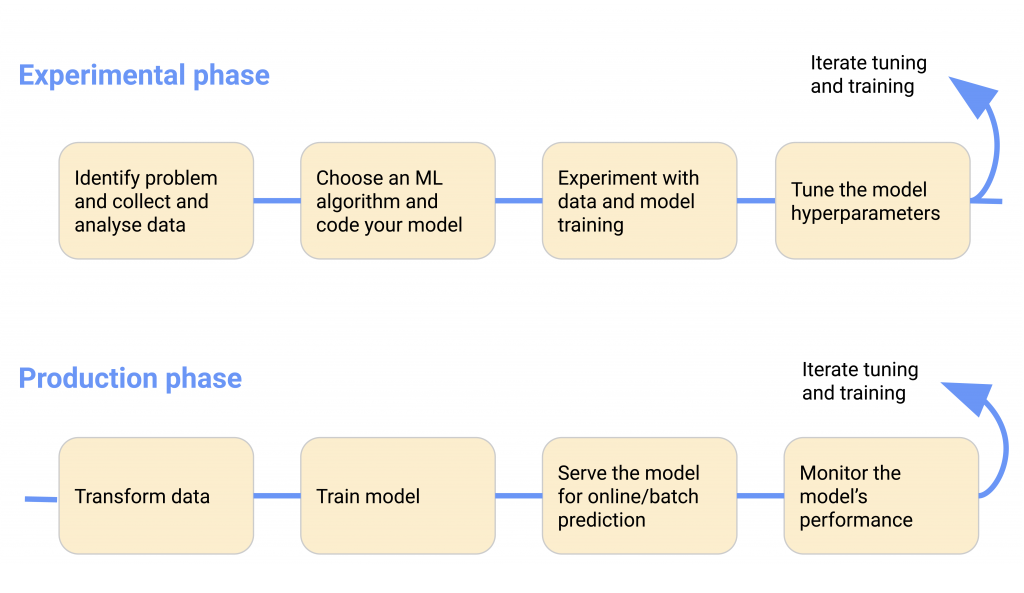 Image source: kubeflow
Image source: kubeflow
Main source page of all the images above: https://www.kubeflow.org/docs/started/kubeflow-overview/
On-premise and Cloud Deployment
Kubeflow has on-premise and cloud deployment capabilities that Google’s Anthos support. Anthos is a hybrid and multi-cloud application platform built on open source technologies, including Kubernetes and Knative. Anthos lets you create a consistent setup across your on-premises and cloud environments, where policy and security automation is possible at scale. Kubeflow can be deployed on IBM Cloud, AWS, and Azure as well.
3. Datarobot
DataRobot is an end-to-end enterprise platform that automates and accelerates every step of your ML workflow. Data Scientists or the operations team can import models programmed using Python, Java, R, Scala, and Go. The system includes frameworks in pre-built environments like Keras, PyTorch, and XGBoost that simplify deployment. You can then test and deploy models on Kubernetes and other ML execution environments that are available via a production-grade REST endpoint. DataRobot lets you monitor service health, accuracy, and data drift and generates reports and alerts for overall performance monitoring.
Components
• REST API-Helps quickly deploy and interact with a DataRobot-built model.
• Model Registry – The Model Registry is the central hub with all your model packages containing a file or set of files with model-related information.
• Governance and Compliance -This component helps comply with your models and
ML workflows with the defined MLOps guidelines and policies.
• Application Server -This component handles authentication, user administration, and project management and provides an endpoint for APIs.
• Modeling workers – This computing resource allows users to train machine learning models in parallel and even generate predictions at times.
• Dedicated prediction servers -Help monitor system health and make real-time decisions using key statistics.
• Docker Containers – This helps run multi-instance services on multiple machines, offering high availability and resilience during disaster recovery. Docker containers allow enterprises to run all of the processes on one server.
Features
1. Monitor MLOps models for service health, data drift, and accuracy.
2. Custom Notifications for user deployment status.
3. Management and replacement of MLOps models along with the documented record of every change that occurs.
4. Establish governance roles and processes for each deployment.
5. Real-time deployments using DataRobot Prediction API & HTTP Status Interpretation.
6. Optimization of Real-Time Model Scoring Request Speed.
7. Batch deployments using Batch Prediction APIs and Parameterized Batch Scoring Command-line Scripts.
Architecture
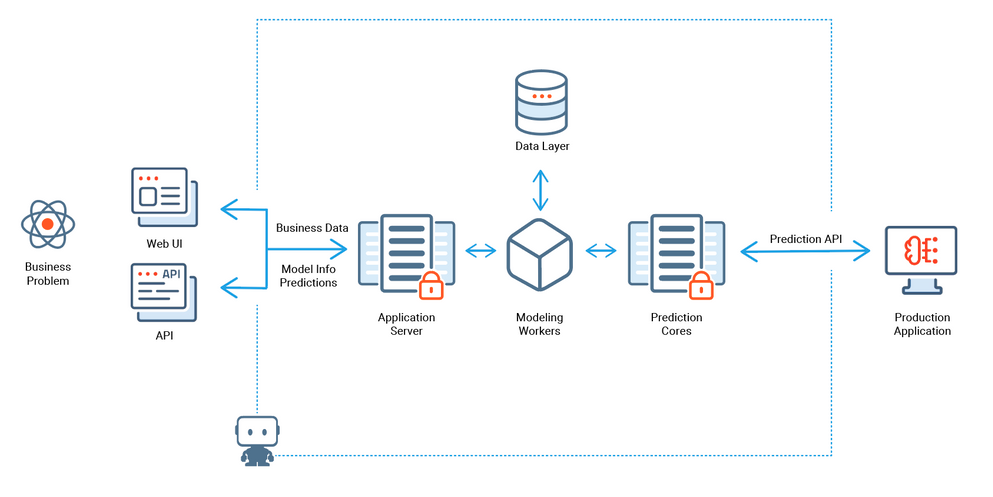 Image source: Datarobot community
Image source: Datarobot community
The web UI and APIs feed business data and model information predictions to the application server.
The App Server handles user administration tasks and authentication. It also acts as the API endpoint.
The queued modeling requests are sent to the modeling workers. These stateless components can be configured to join or leave the environment on-demand.
The data layer is where the trained models are written back. Their accuracy is indicated on the model Leaderboard through the Application Server.
The Dedicated Prediction Server uses key statistics for instant Decisioning and provides data returned to the Application Server.
On-premise and Cloud Deployment
DataRobot can be deployed for on-premise enterprise clients as either a standalone Linux deployment or a Hadoop deployment. Linux deployments allow clients to deploy the platform in multiple locations from physical hardware and VMware clusters. They also help deploy using virtual private cloud (VPC) providers. Hadoop deployments help install in a provisioned Hadoop cluster which saves on hardware costs and simplifies data connectivity.
4. Azure ML
Azure Machine Learning (Azure ML) is a cloud-based service for creating and managing ML workflows and solutions. It helps data scientists and ML engineers leverage data processing and model development frameworks. Teams can scale, deploy and distribute their workloads to the cloud infrastructure at any time.
Components
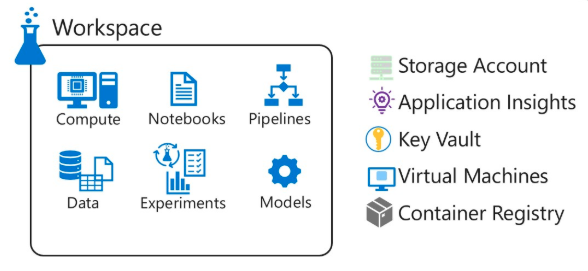 • A Virtual machine (VM) is a device on-premise or in the cloud that can send an HTTP request.
• A Virtual machine (VM) is a device on-premise or in the cloud that can send an HTTP request.
• Azure Kubernetes Service (AKS) is used for application deployment on a Kubernetes cluster.
• Azure Container Registry helps store images for all Docker container deployment types, including DC/OS, Docker Swarm, and Kubernetes.
Features
 Image source: slidetodoc
Image source: slidetodoc
New Additions
More intuitive web service creation – A “training model” can be turned into a “scoring model” with a single click. Azure ML automatically suggests/creates the input and output points of the web service model. Finally, an Excel file can be downloaded and used for web service interactions for feature inputs and scores/predictions outputs.
The ability to train/retrain models through APIs – Developers and data scientists can periodically retrain a deployed model with dynamic data programmatically through an API.
Python support – Custom Python code can be easily added by dragging the “Execute Python Script” workflow task into the model and feeding the code directly into the dialogue box that appears. Python, R, and Microsoft ML algorithms can all be integrated into a unified workflow.
Learn with terabyte-sized data – You can connect to and develop predictive models using “Big Data” sets with the support of “Learning with Counts.”
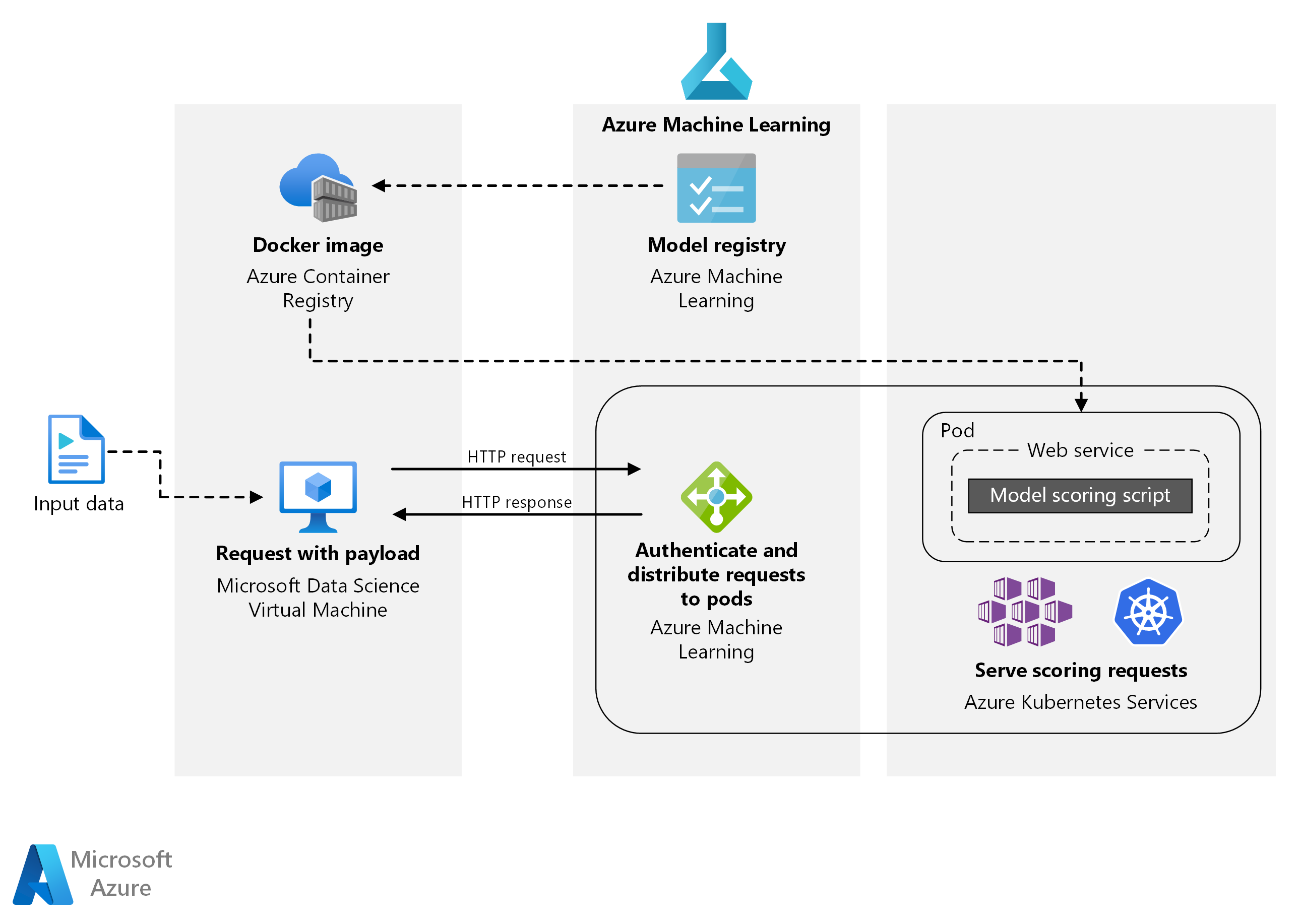
Architecture
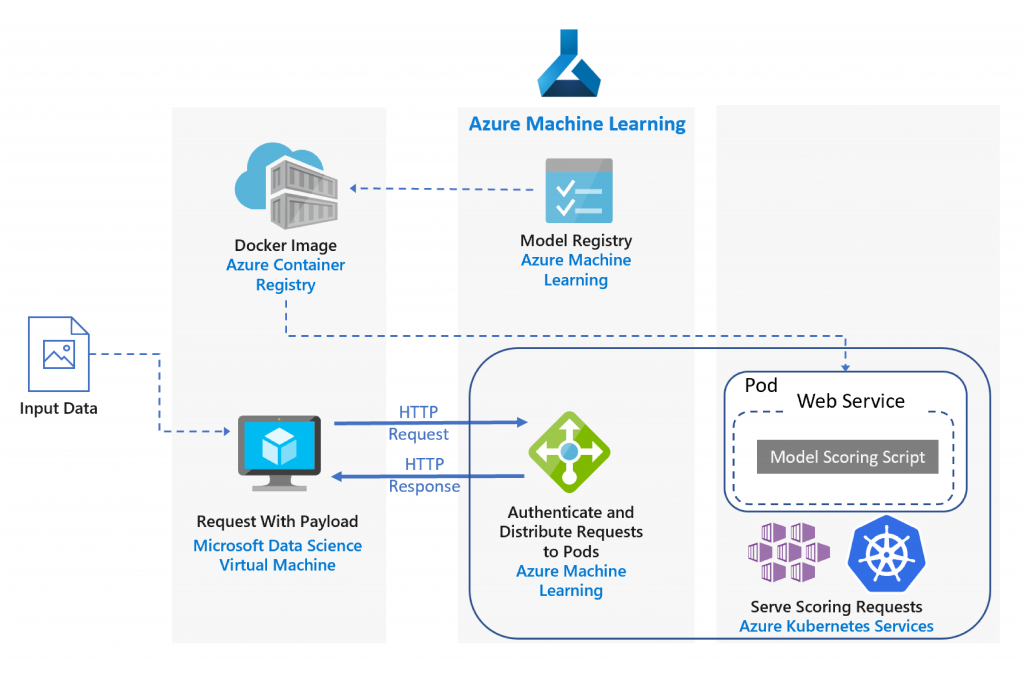 Image source: Microsoft docs
Image source: Microsoft docs
1. The trained model is registered to the ML model registry.
2. Azure ML creates a Docker image that includes the model and the scoring script.
3. It then deploys the Azure Kubernetes Service (AKS), scoring images as a web service.
4. The client sends an HTTP POST request with the question data encoded.
5. The web service created by Azure ML extracts the question from the request.
6. The question is relayed to the Scikit-learn pipeline model for scoring and featurization.
7. The matching FAQ questions with their scores are returned to the client.
On-Premise and other Deployment Options
Azure ML tools can create and deploy models on-premise, in the Azure cloud, and at the edge with Azure IoT edge computing.
Other options include:
• VMs with graphic processing units (GPUs) to help handle complex math and parallel processing requirements of images.
• Field-programmable gate arrays (FPGAs) as-a-service help operate at computer hardware speeds and drastically improve performance.
• Microsoft Machine Learning Server: This provides an enterprise-class server for distributed and parallel workloads for data analytics developed using R or Python. This server runs on Windows, Linux, Hadoop, and Apache Spark.
5. Amazon SageMaker
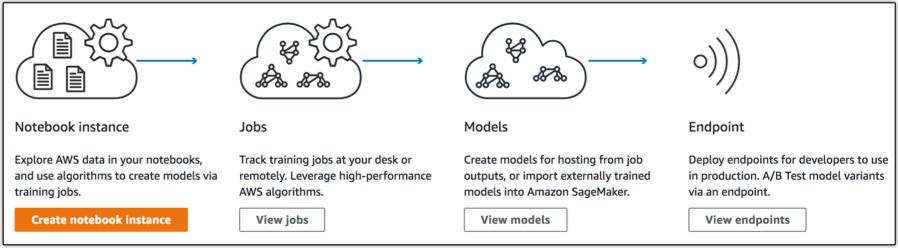
Amazon SageMaker is a fully-managed end-to-end ML service that enables data scientists and developers to build quickly, train, and host ML models at scale. SageMaker allows data labeling and preparation, algorithm selection, model training, tuning, optimization, and deployment to production.
Components
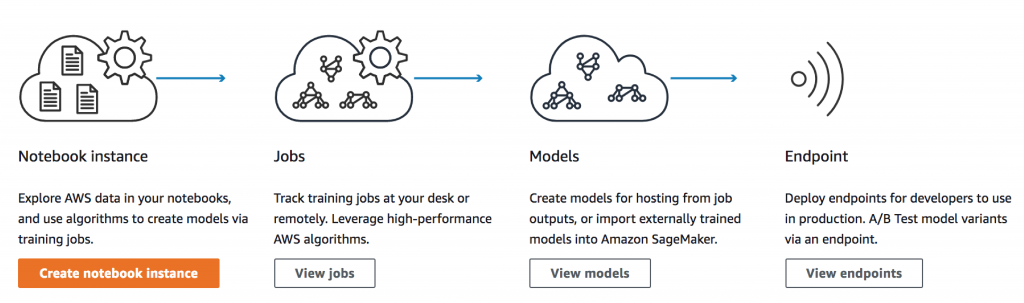 Image source: AWS
Image source: AWS
• Authoring: Zero-setup hosted Jupyter notebook IDEs for data exploration, cleaning, and pre-¬ processing.
• Model Training: A distributed model building, training, and validation service. You can use built-in standard supervised and unsupervised learning algorithms and frameworks or create your¬ training with Docker containers.
• Model Artifacts: Data-dependent model parameters allow you to deploy Amazon SageMaker¬-trained models to other platforms like IoT devices.
• Model Hosting: A model hosting service with HTTPS endpoints for invoking your models to get real-time inferences. These endpoints can scale to support traffic and allow you to A/B test, multiple models simultaneously. Again, you can construct these endpoints using the built-in SDK or provide your configurations with Docker images.
Features
 Image source: slideshare
Image source: slideshare
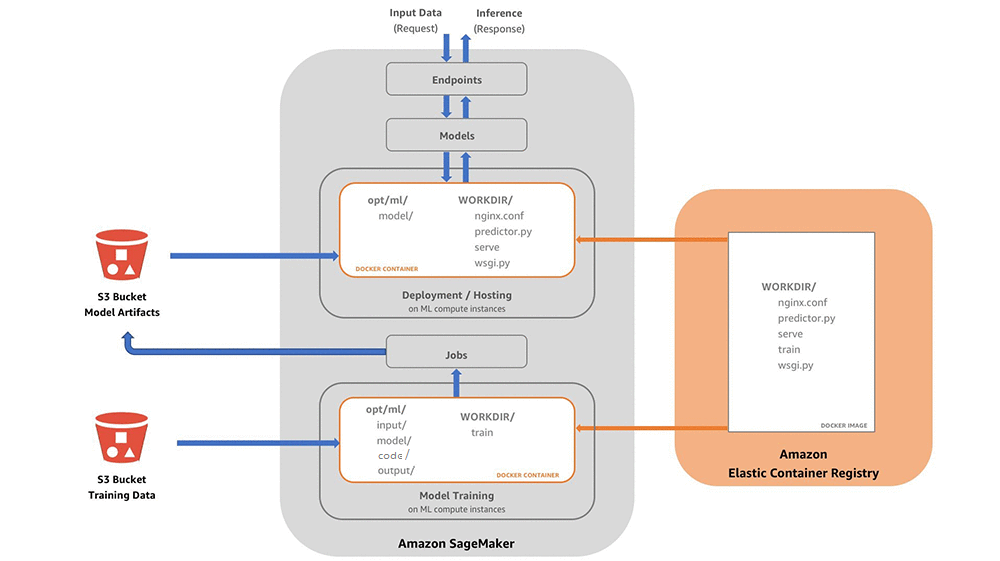
Architecture
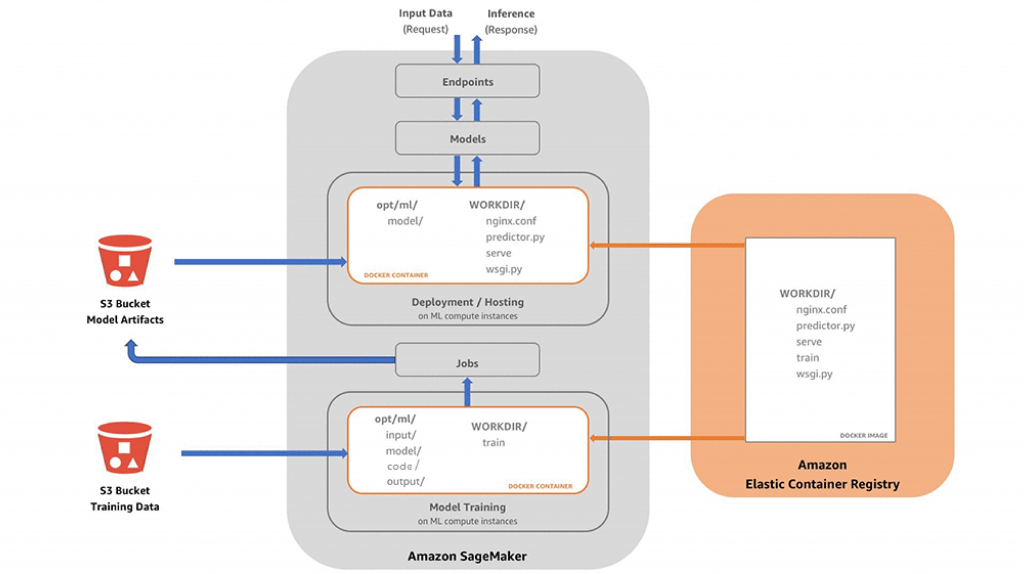 Image source: ML in production
Image source: ML in production
SageMaker is composed of various AWS services. An API is used to “bundle” together these services to coordinate the creation and management of different machine learning resources and artifacts.
On-premise and Cloud Deployment
Once the MLOps model is created, trained, and tested using SageMaker, it can be deployed by creating an endpoint and sending end images through HTTP using AWS SDKs.
This endpoint can be used by an application deployed on AWS (e.g., Lambda functions, Docker Microservices, or applications deployed on EC2s) and applications running on-premise.
MLOps Tools Comparison Snapshot
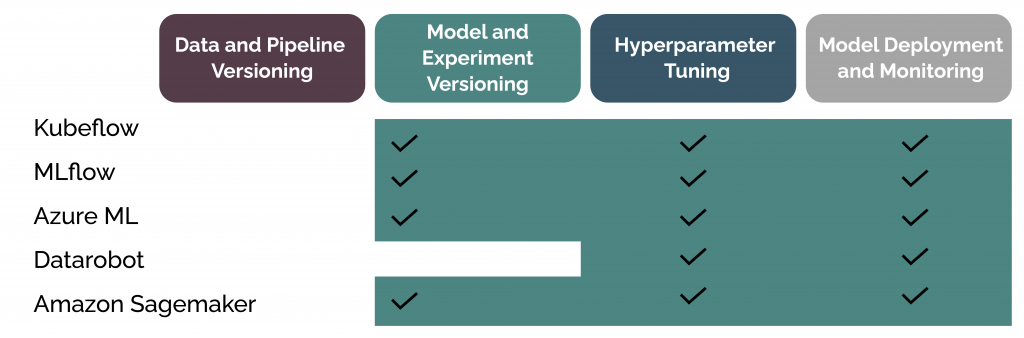
| MLOps Tool | Purpose | Build | Deploy | Monitor | Drag-and-drop | Model Customization |
| AWS SageMaker | It lets you train the Machine Learning model by creating a notebook instance from the SageMaker console along
with proper IAM role and S3 bucket access. |
SageMaker console, Amazon Notebook S3, Apache Spark. | Amazon Hosting Service Model Endpoint | Amazon Model Monitor, Amazon CloudWatch Metrics | NO | YES |
| AZURE ML | It lets Data scientists create separate pipelines for different phases in the ML lifecycle, such as data pipeline, deploy pipeline,
inference pipeline, etc. |
Azure Notebook, ML Designer | Azure ML studio, Real-time endpoint service, Azure pipeline | Azure Monitor | YES | NO |
| DataRobot | It provides a single place to deploy centrally, monitor, manage, and govern all your production ML models, regardless of how they were created and where they were deployed. | Baked-in modeling techniques, drag-and-drop | · Make predictions, a.k.a. drag-and drop
· Deploy · Deploy to Hadoop · DataRobot prime · Download · Prediction Application |
MLOps monitoring agents | YES | YES |
| Kubeflow | It is dedicated to making deployments of ML workflows on Kubernetes simple, portable, and scalable. The goal is not to recreate other services but to provide a straightforward way to deploy the best-of-breed open-source ML systems to diverse infrastructures. | TensorFlow libraries, Google AI Platform, Datalab, Big Query, Data flow, Google Storage, Data Proc for Apache Spark and Hadoop | TensorFlow Extended (TFX) Kubeflow pipeline | ML Monitor API, Google Cloud Logging, Cloud Monitoring Service | YES | YES |
| MLflow | It provides experimentation, tracking, model deployment, and model management services to manage the build, deploy, and monitor phases of ML projects. | Experiment tracking | Model Deployment | Model Management | YES | YES |
Wrapping up
Implementing the right mix of ML models should not be an afterthought but carefully calibrated within the ML lifecycle. Visibility into models runtime behavior benefits data scientists and operations teams to monitor effectiveness while providing the opportunity to detect any shortcomings and embrace functional improvements.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}